Understanding Word Embeddings: A Journey Through Computational Language Representation
The Linguistic Code: Deciphering Machine Understanding
Imagine standing at the intersection of human communication and computational intelligence. Here, words transform from abstract symbols into precise mathematical representations, revealing hidden patterns that connect language across cultures and contexts.
As an artificial intelligence researcher who has spent years exploring the intricate landscapes of machine learning, I‘ve witnessed a remarkable evolution in how computers comprehend language. Word embeddings represent more than just a technical breakthrough – they‘re a profound translation mechanism between human thought and machine processing.
The Origin Story: From Linguistic Puzzles to Mathematical Representations
Our journey begins in the late 20th century when researchers recognized a fundamental challenge: how can machines truly understand the nuanced, contextual nature of human language? Traditional computational approaches treated words as discrete, disconnected entities – unable to capture the rich semantic relationships that humans intuitively understand.
Consider the word "bank". In human communication, this single term carries multiple meanings – a financial institution, a river‘s edge, or even an action of tilting an aircraft. Traditional computational methods would struggle to distinguish these contexts, treating each occurrence as a separate, unrelated entity.
Word embeddings emerged as an elegant solution to this complexity, transforming linguistic ambiguity into precise mathematical representations.
Mathematical Foundations of Word Embeddings
At their core, word embeddings are sophisticated mathematical transformations that map words into dense vector spaces. These vector representations capture semantic relationships, allowing machines to understand contextual similarities and differences.
The Vector Space Revolution
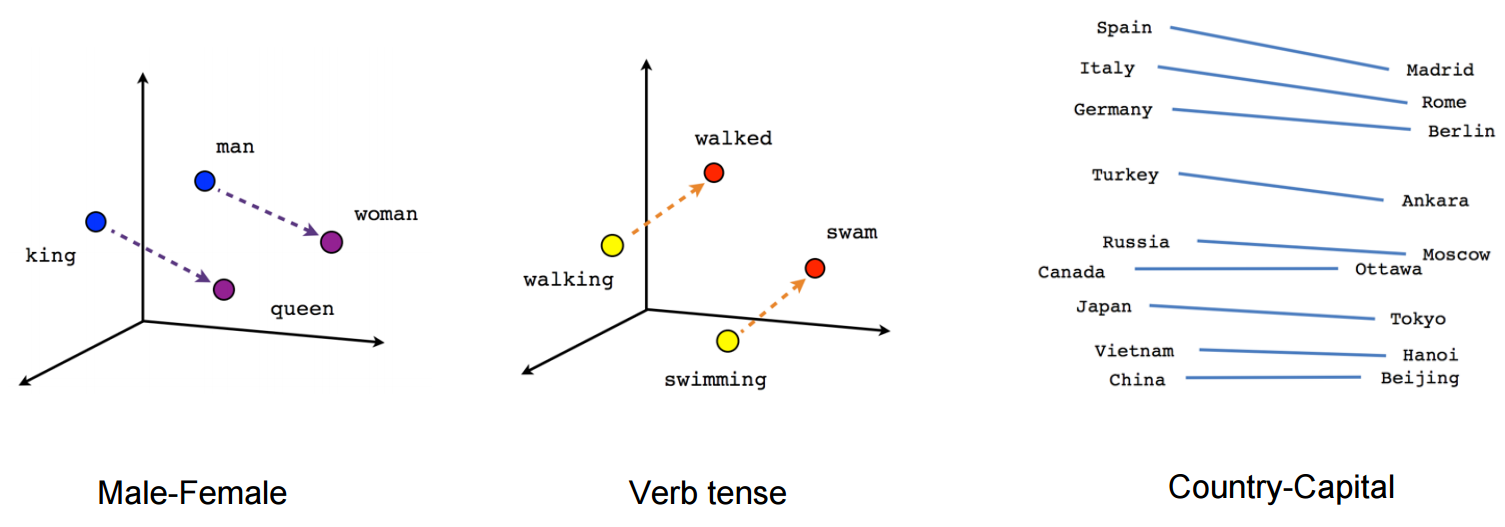
Imagine a multidimensional mathematical landscape where words are not isolated points but interconnected regions with fluid boundaries. In this space, semantically related words cluster together, creating intricate networks of linguistic meaning.
[Vec("King") – Vec("Man") + Vec("Woman") \approx Vec("Queen")]This remarkable equation demonstrates how word embeddings capture complex semantic relationships through pure mathematical manipulation.
Computational Linguistic Techniques
Count Vectors: The First Generation
Count vectors represent the earliest computational approach to word representation. By counting word occurrences across documents, researchers created initial numerical representations of linguistic data.
def create_count_vector(corpus):
"""
Generate count vector representation of text corpus
Args:
corpus (list): Collection of text documents
Returns:
numpy.array: Numerical representation of word frequencies
"""
vectorizer = CountVectorizer()
count_matrix = vectorizer.fit_transform(corpus)
return count_matrix.toarray()TF-IDF: Weighted Semantic Significance
TF-IDF (Term Frequency-Inverse Document Frequency) introduced a more nuanced approach by assigning weights based on word importance across documents.
[TF-IDF(term, document) = TF(term) * \log(\frac{Total Documents}{Documents Containing Term})]This technique allowed more sophisticated semantic analysis by reducing the impact of common, less informative words.
Neural Network Embeddings: Word2Vec Revolution
Word2Vec represented a quantum leap in computational linguistics, utilizing neural network architectures to generate dense, meaningful word representations.
Continuous Bag of Words (CBOW)
CBOW predicts a target word based on surrounding context words, creating a probabilistic approach to word representation. By training on massive text corpora, CBOW models learn intricate semantic relationships.
Skip-Gram: Contextual Prediction
Skip-gram inverts the CBOW approach, predicting context words from a target word. This technique often produces more nuanced embeddings, especially for larger datasets.
Practical Implementation Strategies
Implementing word embeddings requires careful consideration of computational resources, dataset characteristics, and specific use cases.
Performance Considerations
- Embedding Dimensionality
- Training Corpus Selection
- Computational Complexity
- Domain-Specific Adaptations
Code Example: Custom Word Embedding Training
from gensim.models import Word2Vec
class WordEmbeddingTrainer:
def __init__(self, corpus, vector_size=100):
self.corpus = corpus
self.vector_size = vector_size
self.model = None
def train(self):
self.model = Word2Vec(
self.corpus,
vector_size=self.vector_size,
window=5,
min_count=1
)
return self.modelEmerging Research Frontiers
Contextual Embeddings
Recent developments like BERT and GPT have pushed word embedding techniques into new territories, creating context-aware representations that adapt dynamically to linguistic nuances.
Cross-Lingual Techniques
Researchers are developing embedding techniques that transcend language barriers, creating universal representations that capture semantic meanings across linguistic boundaries.
Ethical Considerations
As word embedding technologies advance, critical ethical questions emerge:
- How do we mitigate inherent biases in training data?
- Can we create more inclusive, representative linguistic models?
- What are the potential societal implications of advanced language representations?
The Future of Computational Linguistics
Word embeddings represent more than a technical achievement – they‘re a profound bridge between human cognition and computational processing. As research continues, we‘ll witness increasingly sophisticated methods of capturing linguistic complexity.
Our journey of understanding language through mathematics has only just begun.
Invitation to Explore
For researchers, developers, and curious minds: the world of word embeddings offers an endlessly fascinating landscape of discovery. Embrace the complexity, challenge existing paradigms, and continue pushing the boundaries of computational understanding.




