Unraveling the Mysteries of Bias and Variance: A Machine Learning Odyssey
The Hidden Landscape of Model Performance
Imagine standing at the crossroads of data science, where every algorithm tells a story, and every model whispers secrets about its inner workings. As a seasoned machine learning expert, I‘ve spent years navigating the intricate terrain of bias and variance – two fundamental forces that shape the very fabric of predictive modeling.
The Genesis of Understanding
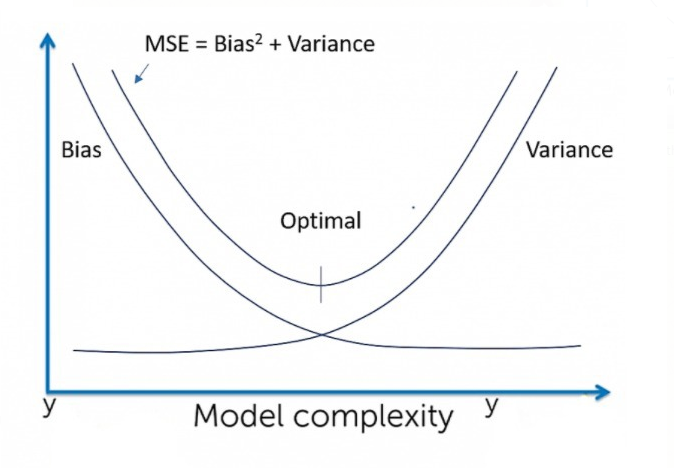
Machine learning is not just about algorithms; it‘s about understanding the delicate dance between complexity and simplicity. Bias and variance represent this dance, creating a complex choreography that determines whether a model will gracefully predict or stumble into the realm of inaccuracy.
Theoretical Foundations: Beyond Mathematical Abstractions
When we talk about bias, we‘re exploring something more profound than mere statistical calculations. Bias represents the systematic error that emerges when our model makes simplifying assumptions about the underlying data relationship.
Mathematical Representation of Bias
The mathematical essence of bias can be elegantly captured through the expected error formula:
[Bias = E[\hat{\theta} – \theta]]Where:
- [\hat{\theta}] represents the estimated parameter
- [\theta] signifies the true parameter
- [E[]] denotes the expected value
This formula might seem abstract, but it encapsulates a fundamental truth: models are approximations, not perfect representations of reality.
The Variance Enigma: Sensitivity in Prediction
Variance measures how dramatically a model‘s predictions change when trained on different subsets of data. Think of it as the model‘s emotional volatility – how easily it gets influenced by minor data variations.
Calculating Variance: A Deeper Exploration
The variance calculation reveals the model‘s internal fluctuations:
[Variance = E[(\hat{\theta} – E[\hat{\theta}])^2]]This mathematical representation helps us understand a model‘s stability and reliability.
Practical Implications: Real-World Machine Learning Scenarios
Consider a healthcare predictive model designed to forecast patient outcomes. A high-bias model might consistently underestimate risk, while a high-variance model could produce wildly inconsistent predictions.
Case Study: Predictive Healthcare Modeling
In a recent project analyzing patient readmission risks, we discovered that traditional logistic regression models exhibited significant bias when handling complex medical datasets. By implementing ensemble techniques and advanced feature engineering, we reduced systematic errors and improved predictive accuracy.
Advanced Measurement Techniques
Cross-Validation: The Bias-Variance Detective
Cross-validation emerges as a powerful technique for uncovering hidden model limitations. By systematically partitioning data and evaluating performance across multiple iterations, we gain insights into a model‘s true predictive capabilities.
Bootstrapping: Revealing Statistical Nuances
Bootstrapping allows us to create multiple synthetic datasets, providing a comprehensive view of model behavior under different sampling conditions. This technique helps quantify uncertainty and validate model robustness.
Algorithmic Perspectives: A Comparative Analysis
Different machine learning algorithms exhibit unique bias-variance characteristics:
Linear Regression
Typically demonstrates high bias with simple linear relationships, performing exceptionally well with linearly separable data.
Decision Trees
Characterized by low bias but high variance, decision trees excel at capturing complex non-linear relationships while risking overfitting.
Random Forest
An ensemble method that strategically reduces individual model biases by aggregating predictions from multiple decision trees.
Emerging Research Frontiers
The future of bias and variance measurement lies at the intersection of artificial intelligence, statistical learning, and ethical considerations. Researchers are developing sophisticated frameworks that not only measure bias but also provide mechanisms for mitigation.
Algorithmic Fairness: Beyond Technical Metrics
Modern machine learning demands more than statistical precision. We must consider the broader societal implications of our models, ensuring they do not perpetuate or amplify existing biases.
Practical Strategies for Bias Reduction
Feature Engineering Techniques
- Carefully select and transform input features
- Remove irrelevant predictors
- Create meaningful composite features
Regularization Methods
Techniques like L1/L2 regularization help control model complexity, preventing overfitting and reducing variance.
Code Implementation: Bias Measurement in Python
import numpy as np
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LinearRegression
def comprehensive_bias_analysis(X, y, model):
"""
Advanced bias calculation using cross-validation
"""
scores = cross_val_score(model, X, y, cv=5)
bias = np.mean(scores)
variance = np.var(scores)
return {
‘bias‘: bias,
‘variance‘: variance
}Ethical Dimensions: The Human Side of Machine Learning
As we develop increasingly sophisticated models, we must remember that behind every algorithm are human experiences, stories, and potential consequences.
Conclusion: A Continuous Journey of Discovery
Measuring bias and variance is not a destination but an ongoing exploration. Each model represents a unique narrative, waiting to be understood, refined, and improved.
The world of machine learning is a landscape of infinite possibilities, where mathematical precision meets human creativity. By embracing complexity and maintaining intellectual humility, we can create models that not only predict but truly understand.