Unraveling Topic Modeling with LDA: A Comprehensive Journey into Text Analysis
The Fascinating World of Hidden Textual Patterns
Imagine walking through a vast library, surrounded by thousands of books, each whispering its unique story. As a machine learning researcher, I‘ve always been captivated by the challenge of understanding these narratives – not just reading them, but truly comprehending their underlying essence.
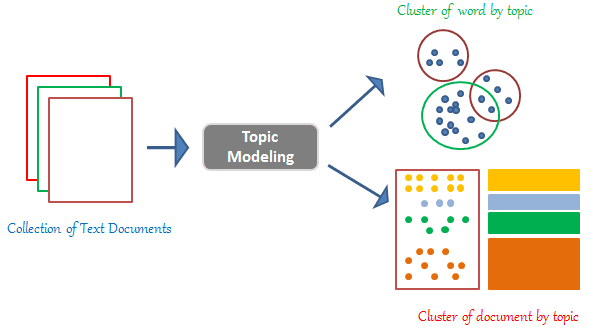
Topic modeling represents our computational attempt to decode these complex textual landscapes. It‘s like having a magical lens that can peer into the heart of documents, revealing hidden themes and connections that might escape human perception.
The Origins of Our Computational Quest
The journey of topic modeling begins with a fundamental human curiosity: How do we make sense of massive text collections? Before sophisticated algorithms, researchers relied on manual categorization – a time-consuming and often subjective process.
Latent Dirichlet Allocation (LDA) emerged as a revolutionary approach, offering a probabilistic framework to automatically discover semantic structures within text. Developed by David Blei, Andrew Ng, and Michael Jordan in 2003, LDA transformed our understanding of text analysis.
Mathematical Foundations: Decoding the Probabilistic Magic
At its core, LDA operates like an intricate probabilistic machine, generating documents through a sophisticated generative process. Let me break down the mathematical elegance that powers this technique.
The fundamental equation representing LDA can be expressed as:
[P(Documents | Topics) = \int P(Documents | Topics, \theta) P(\theta) d\theta]Where:
- [P(Documents)] represents the probability of document generation
- [\theta] symbolizes topic distributions
- [P(\theta)] captures the Dirichlet distribution‘s inherent complexity
The Generative Process Unveiled
Picture LDA as a document creation mechanism with these steps:
- Select a number of topics
- For each document:
- Sample topic proportions from a Dirichlet distribution
- Generate words by sampling from topic-specific word distributions
This process mimics how humans might conceptualize and construct textual content, making LDA remarkably intuitive.
Practical Implementation: Transforming Theory into Action
Preprocessing: The Critical First Step
Before diving into topic modeling, preparing your text is crucial. Think of preprocessing like preparing ingredients for a complex recipe – each step matters immensely.
import numpy as np
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.decomposition import LatentDirichletAllocation
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
class TextTopicModeler:
def __init__(self, num_topics=10):
self.num_topics = num_topics
self.stopwords = set(stopwords.words(‘english‘))
def preprocess_text(self, text):
# Advanced text cleaning
tokens = word_tokenize(text.lower())
cleaned_tokens = [
token for token in tokens
if token.isalnum() and token not in self.stopwords
]
return ‘ ‘.join(cleaned_tokens)
def extract_topics(self, documents):
vectorizer = CountVectorizer(max_df=0.95, min_df=2)
doc_term_matrix = vectorizer.fit_transform(documents)
lda_model = LatentDirichletAllocation(
n_components=self.num_topics,
random_state=42,
learning_method=‘online‘
)
lda_output = lda_model.fit_transform(doc_term_matrix)
return lda_model, lda_outputReal-World Applications: Beyond Academic Curiosity
Industry Transformations
Topic modeling isn‘t just an academic exercise – it‘s a powerful tool reshaping multiple industries:
Customer Insights
Companies like Amazon and Netflix leverage topic modeling to understand customer preferences, generating personalized recommendations that feel almost magical.
Scientific Research
Researchers use LDA to analyze vast academic corpora, discovering emerging research trends and interconnected domains.
Legal and Compliance
Law firms employ topic modeling to quickly categorize and analyze extensive legal documents, saving countless hours of manual review.
Advanced Techniques and Emerging Trends
As machine learning evolves, so do topic modeling techniques. Researchers are exploring hybrid approaches combining LDA with deep learning architectures, creating more nuanced and contextually aware models.
Challenges and Limitations
Despite its power, LDA isn‘t without challenges:
- Interpretability of generated topics
- Computational complexity
- Sensitivity to preprocessing choices
The Human Element in Computational Discovery
What fascinates me most about topic modeling is its reflection of human cognitive processes. We‘re essentially teaching machines to read between the lines, to understand context and meaning beyond literal interpretation.
Conclusion: A Continuing Journey of Discovery
Topic modeling represents more than a technical technique – it‘s a window into understanding how information interconnects, how meaning emerges from complexity.
As we continue pushing computational boundaries, techniques like LDA remind us that technology is fundamentally about understanding – about seeing patterns invisible to the naked eye.
Your Next Steps
Experiment. Play. Break things. The most profound insights often emerge from curiosity and persistent exploration.
Happy modeling!





