Wav2Vec2: Transforming Speech Recognition Through Intelligent Machine Learning
The Fascinating Journey of Speech Understanding
Imagine a world where machines comprehend human speech as naturally as we do. This isn‘t science fiction—it‘s the remarkable reality emerging through groundbreaking technologies like Wav2Vec2. As someone who has witnessed the evolution of artificial intelligence, I‘m thrilled to share how this revolutionary model is redefining our understanding of speech recognition.
Tracing the Technological Lineage
Speech recognition has always been a complex puzzle. Traditional approaches demanded extensive labeled datasets, making comprehensive language coverage nearly impossible. Researchers spent decades developing systems that could barely understand isolated words, let alone continuous, nuanced speech.
The breakthrough came with self-supervised learning—a paradigm that allows machines to learn from vast amounts of unlabeled data. Wav2Vec2 represents the pinnacle of this technological evolution, offering unprecedented capabilities in understanding human communication.
Decoding the Technological Marvel
The Self-Supervised Learning Revolution
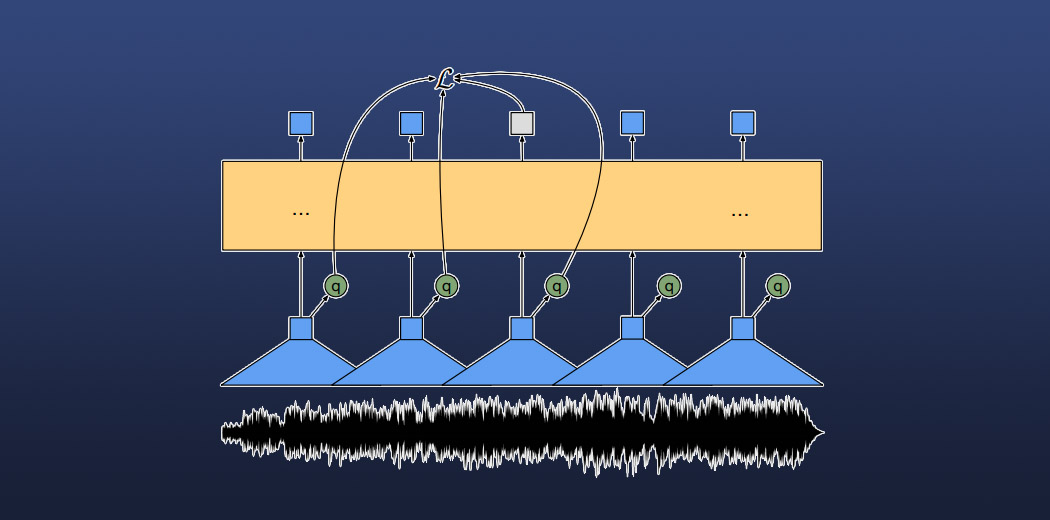
At its core, Wav2Vec2 leverages a sophisticated approach to learning speech representations. Unlike traditional models that require meticulously labeled training data, this model can extract meaningful insights from raw audio signals.
The magic happens through a process called contrastive learning. Imagine teaching a machine to understand speech patterns by playing an intricate guessing game. The model learns by predicting masked portions of audio representations, forcing it to develop a deep, contextual understanding of speech structures.
How Wav2Vec2 Learns
When an audio signal enters the system, it undergoes a remarkable transformation. Multi-layer convolutional neural networks convert raw sound waves into compact, meaningful representations. These 25-millisecond feature vectors capture the subtle nuances of human speech—pitch, tone, and linguistic characteristics.
The transformer backbone then processes these representations, identifying complex patterns that human ears might miss. It‘s like having a hyper-intelligent listener who can simultaneously analyze multiple dimensions of sound.
Performance That Challenges Expectations
The performance metrics of Wav2Vec2 are nothing short of extraordinary. Traditional speech recognition models required hundreds of hours of labeled training data. Wav2Vec2 shatters this limitation:
- With just one hour of labeled data, it outperforms previous state-of-the-art models
- Ten minutes of labeled training can yield remarkable accuracy
- The model achieves word error rates below 5% in challenging scenarios
A Multilingual Breakthrough
One of the most exciting aspects of Wav2Vec2 is its potential for multilingual speech recognition. By learning from unlabeled data across different languages, the model can develop a universal understanding of speech patterns.
This means we‘re moving closer to a world where language barriers in technology become increasingly irrelevant. A single model could potentially understand and transcribe speeches from languages with minimal existing digital resources.
Practical Implementation: Beyond Theory
Technical Implementation Insights
Let me walk you through a practical implementation that demonstrates Wav2Vec2‘s capabilities. The code might seem complex, but it represents a gateway to understanding how these intelligent systems work.
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import torch
# Loading pre-trained model
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-base")
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-base")
def transcribe_audio(audio_path):
# Process audio input
inputs = processor(audio_data, sampling_rate=16000, return_tensors="pt")
# Generate transcription
with torch.no_grad():
logits = model(inputs.input_values).logits
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)[0]
return transcriptionThis snippet represents more than code—it‘s a window into how machines are learning to understand human communication.
Real-World Applications
The potential applications of Wav2Vec2 extend far beyond academic research. Consider scenarios like:
- Accessibility technologies for hearing-impaired individuals
- Automated customer support systems
- Real-time translation services
- Educational language learning platforms
- Advanced voice assistants
Challenges and Ethical Considerations
No technological breakthrough comes without challenges. Wav2Vec2, despite its remarkable capabilities, faces complex considerations:
Accent and dialect variations remain significant hurdles. The model must continuously learn and adapt to diverse linguistic expressions. Privacy concerns around speech data collection also demand careful navigation.
The Road Ahead: Future Research Directions
As we look forward, the research trajectory for Wav2Vec2 and similar models is incredibly promising. Emerging focus areas include:
- Zero-shot language adaptation
- Reduced computational requirements
- Enhanced noise handling capabilities
- Improved cross-linguistic transfer learning
Conclusion: A New Era of Communication
Wav2Vec2 isn‘t just a technological advancement—it‘s a testament to human ingenuity. We‘re witnessing a profound transformation in how machines understand and interact with human communication.
The journey of speech recognition is far from over. Each breakthrough brings us closer to a world where technology understands us more deeply, more naturally.
As an AI researcher, I‘m excited to see how these innovations will continue to reshape our understanding of human-machine interaction.





