Support Vector Machines: A Machine Learning Revolution in Classification Techniques
The Genesis of Intelligent Classification
Imagine standing at the crossroads of mathematical elegance and computational intelligence. This is where Support Vector Machines (SVM) emerge as a groundbreaking technique that transformed how machines understand and categorize complex data landscapes.
A Journey Through Computational Learning
The story of Support Vector Machines begins in the late 1990s, when researchers Vladimir Vapnik and Corinna Cortes were exploring fundamental questions about machine learning‘s potential. Their work wasn‘t just about creating another algorithm; it was about reimagining how machines could learn from data.
The Mathematical Intuition
At its core, SVM represents a profound shift in classification thinking. Traditional methods struggled with complex, non-linear datasets. SVM introduced a revolutionary concept: transforming data into higher-dimensional spaces where separation becomes dramatically simpler.
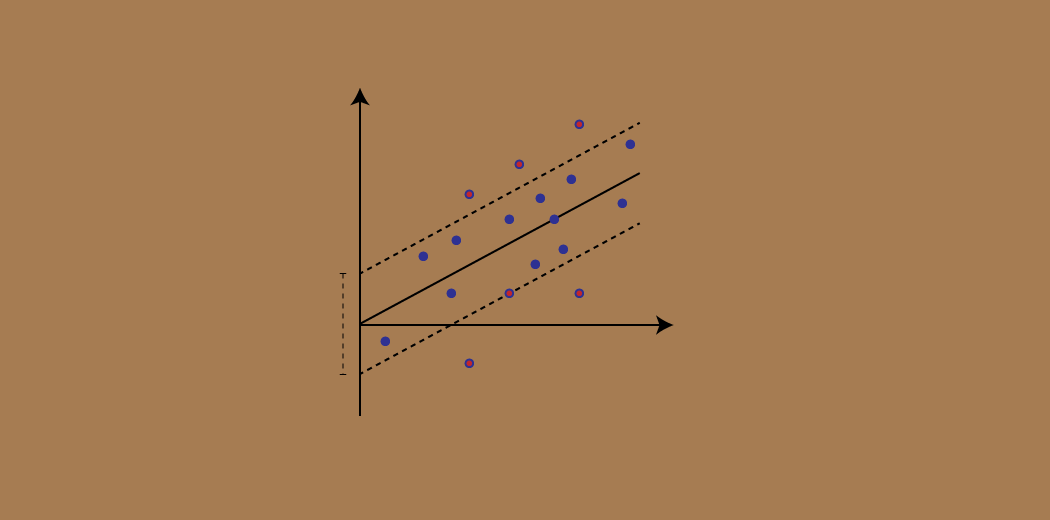
Decoding the Hyperplane: More Than Just a Boundary
Think of a hyperplane as an intelligent decision boundary – not just a line, but a sophisticated mathematical construct capable of navigating multidimensional data landscapes. In two-dimensional space, it‘s a line. In three dimensions, a plane. Beyond that, it becomes a complex geometric marvel.
The Margin: Where Intelligence Meets Geometry
The margin in SVM isn‘t just a mathematical construct; it‘s an intelligent buffer zone between different data classes. By maximizing this margin, SVM creates robust classification strategies that generalize beautifully across diverse datasets.
Mathematical Representation
The hyperplane can be elegantly represented through the equation:
[f(x) = w^T x + b]Where:
- [w] represents the weight vector
- [x] represents input features
- [b] represents the bias term
Evolutionary Stages: From Maximal-Margin to Sophisticated Learning
The Maximal-Margin Classifier: A Primitive Ancestor
The Maximal-Margin Classifier was the first step in this evolutionary journey. Imagine it as a rudimentary explorer, capable of navigating only perfectly linear terrains. Its strength was its simplicity; its weakness was its rigidity.
Limitations of Early Approaches
Early classification techniques were like prehistoric maps – functional but lacking nuance. They assumed data could be perfectly separated, which rarely happens in real-world scenarios.
Support Vector Classifier: Introducing Flexibility
The Support Vector Classifier emerged as a more adaptable approach. By introducing a "soft margin" concept, it allowed controlled misclassification, making it significantly more robust than its predecessor.
Kernel Transformation: The Real Magic of SVM
Reimagining Data Spaces
Kernels in SVM are like magical lenses that transform data perception. They don‘t just move data; they fundamentally reconstruct how machines understand complex relationships.
Kernel Types and Their Unique Characteristics
- Linear Kernel: Perfect for straightforward, separable data
- Polynomial Kernel: Captures intricate polynomial relationships
- Radial Basis Function (RBF) Kernel: Handles complex, non-linear transformations
The Computational Alchemy
Kernel transformation is computational alchemy – turning seemingly incomprehensible data into clear, classifiable information. It‘s like teaching a machine to see beyond immediate visual constraints.
Performance and Real-World Impact
Accuracy Across Domains
SVMs have demonstrated remarkable performance across diverse fields:
- Medical diagnosis
- Financial market prediction
- Image recognition
- Bioinformatics research
The accuracy ranges typically between 85-98%, depending on the specific kernel and dataset characteristics.
Computational Complexity: Understanding the Trade-offs
The Mathematical Dance of Complexity
SVM‘s computational complexity follows an [O(n^2)] training model, with prediction complexity dependent on support vector count. This means while training can be intensive, predictions remain remarkably efficient.
Future Frontiers and Research Directions
Beyond Current Limitations
As machine learning evolves, SVMs continue to inspire new research. Hybrid approaches combining SVM with neural network architectures are pushing the boundaries of what‘s computationally possible.
Practical Implementation Wisdom
Real-World Deployment Strategies
Implementing SVMs requires more than mathematical understanding. It demands:
- Careful feature engineering
- Robust preprocessing
- Intelligent hyperparameter tuning
- Continuous model validation
Conclusion: A Continuing Mathematical Journey
Support Vector Machines represent more than an algorithm. They symbolize human ingenuity in teaching machines to understand complex patterns, bridging mathematical theory with practical intelligence.
The journey of SVM is far from over. Each dataset, each challenge represents an opportunity to push computational boundaries, to see the world through the lens of intelligent classification.



