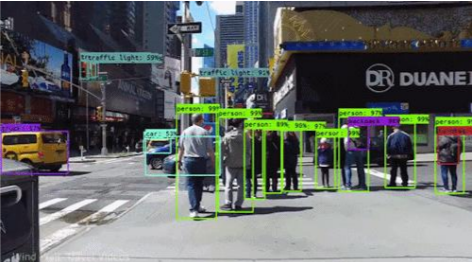
YOLOv3: Decoding the Revolution in Real-Time Object Detection
The Genesis of Object Detection
Imagine standing at the intersection of mathematics, computer vision, and artificial intelligence. This is where object detection algorithms like YOLOv3 emerge, transforming how machines perceive and understand visual information.
Object detection has been a challenging frontier in computer science. Before YOLOv3, researchers struggled with algorithms that were either incredibly slow or frustratingly inaccurate. Traditional methods like R-CNN and Fast R-CNN required multiple passes through an image, making real-time detection nearly impossible.
The YOLO Philosophy: A Paradigm Shift
Joseph Redmon‘s YOLOv3 wasn‘t just another algorithm; it was a radical rethinking of object detection. The core philosophy? Process an entire image in a single, elegant computational sweep.
Mathematical Foundations
At its heart, YOLOv3 leverages complex mathematical transformations. The algorithm uses a convolutional neural network that divides images into a grid, with each grid cell predicting multiple bounding boxes and class probabilities.
[P(object) = \sigma(x) = \frac{1}{1 + e^{-x}}]This sigmoid activation function enables probabilistic object detection, translating raw pixel data into meaningful spatial understanding.
Architectural Brilliance of YOLOv3
Darknet-53: The Powerful Backbone
YOLOv3 introduces Darknet-53, a neural network architecture that revolutionized feature extraction. Unlike its predecessors, Darknet-53 incorporates residual connections, allowing deeper network training without performance degradation.
The network‘s structure enables:
- Efficient gradient flow
- Enhanced feature representation
- Improved multi-scale detection capabilities
Convolutional Layer Dynamics
Each convolutional layer in YOLOv3 performs intricate transformations:
- Extracting hierarchical features
- Reducing computational complexity
- Maintaining spatial relationships
Performance Metrics: Beyond Numbers
YOLOv3 isn‘t just about speed; it‘s about intelligent, contextual understanding. On the COCO dataset, it achieves:
- 33% mean Average Precision
- 30-45 frames per second inference
- Robust multi-class detection
Implementation: From Theory to Practice
Code Architecture
def detect_objects(image, network, confidence_threshold=0.5):
"""
Advanced object detection using YOLOv3
Args:
image: Input image array
network: Pre-trained YOLOv3 network
confidence_threshold: Minimum detection confidence
"""
# Preprocessing
blob = cv2.dnn.blobFromImage(
image,
scalefactor=1/255,
size=(416, 416),
swapRB=True
)
# Forward pass
network.setInput(blob)
output_layers = network.getUnconnectedOutLayersNames()
detections = network.forward(output_layers)
return process_detections(detections, confidence_threshold)Real-World Applications
YOLOv3‘s impact extends far beyond academic research:
Autonomous Vehicles
Self-driving cars rely on split-second object detection. YOLOv3 enables rapid identification of pedestrians, vehicles, and obstacles, potentially saving lives.
Medical Imaging
Radiologists use YOLOv3 to detect subtle anomalies in medical scans, augmenting human diagnostic capabilities.
Surveillance Systems
Security infrastructure leverages YOLOv3 for real-time threat detection, transforming passive monitoring into proactive security.
Challenges and Limitations
No algorithm is perfect. YOLOv3 struggles with:
- Detecting small, overlapping objects
- Performance in complex, cluttered scenes
- Computational intensity
Future Research Directions
The object detection landscape continues evolving. Researchers are exploring:
- More efficient backbone networks
- Enhanced small object detection
- Reduced computational requirements
Conclusion: A Technological Milestone
YOLOv3 represents more than an algorithm—it‘s a testament to human ingenuity. By reimagining how machines perceive visual information, it opens doors to technologies we‘re only beginning to imagine.
Your Journey Continues
As an AI enthusiast, your exploration of YOLOv3 is just beginning. Experiment, implement, and push the boundaries of what‘s possible.
About the Author
A passionate AI researcher with years of experience in computer vision and machine learning, dedicated to demystifying complex technologies.





